
When trying to determine a batter’s overall offensive value using a single statistic, one of the most popular metrics to use is the weighted on-base average (wOBA). wOBA is calculated as a ratio of a linear combination of “outcome” statistics (unintentional walks, hit-by-pitches, singles, doubles, triples, and home runs) divided by, essentially, the number of plate appearances.
With that being said, could one predict whether a given player’s wOBA will be above a certain threshold using “process” statistics such as plate discipline and batted ball parameters? In particular, if we know a player’s, say, zone contact rate, chase rate, and average exit velocity, could we predict with any confidence whether that particular player’s wOBA will be above, say, .320?
Using Statcast data and a bit of machine learning, I have decided to train a shallow neural network to try to do just that. I will post snapshots of the Jupyter Notebook throughout the analysis to make it a little easier to follow.
Dataset
My dataset was downloaded from Statcast (creating a custom leaderboard) and included all qualified batter-seasons from 2015 until June 29th, 2021 – 2015 being the first year for which Statcast data are available. This resulted in a set of 989 player-seasons.
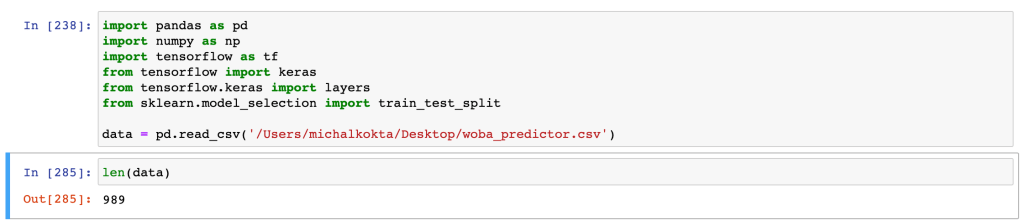
For every player-season, I collected the following nine statistics: wOBA, exit velocity average, barrel batted rate, zone swing percentage, zone swing and miss percentage, zone contact percentage, out-of-zone swing percentage, out-of-zone swing and miss percentage, and out-of-zone contact percentage.
I also created a column that was either “1” if wOBA was >= .320 for that particular player-season, and “0” otherwise. This would be the “true label” the neural network would try to predict. I picked the .320 threshold for wOBA, as that is roughly the league-average. In effect, the network would learn to differentiate between a below-average offensive performer, and an above-average one. Finally, I normalized all the column inputs, as, for example, the exit velocities are on a different scale than the statistics expressed in percentages.
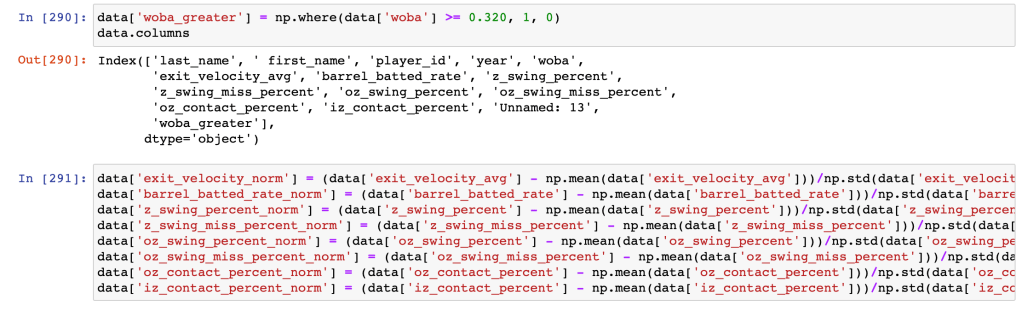
Network Architecture
After a bit of trial and error, I settled on the following network architecture. The input layer had either six, seven, or eight units, depending on how many of the features I used in that particular scenario (this will make more sense further along in the analysis). Following the input layer, there were three fully connected layers with 8 units each, and a single-unit output layer, making the prediction. This is a binary classification problem – i.e. the network will make a prediction of either “1” if it thinks the wOBA of the batter will be greater than or equal to .320 given the input data, or “0” if it thinks the wOBA will be less than .320 – and so a single neuron in the output layer is sufficient. Below is a visual representation with six units in the input layer.

How did I arrive at 8 units in a hidden layer? Since at most I would use 8 input features, I picked that as the number of units in the first hidden layer. I wanted to keep the number of units consistent across layers for simplicity. And how did I decide on three hidden layers? I simply did a run with two hidden layers, and then one with three, and I got better results with three. Going to four started overfitting the training data, and so I settled on three hidden layers.
(For the sake of brevity I won’t go into detail of activation functions, regularization, loss functions etc. here in the body of the article. I will link to the code at the bottom, and feel free to hit me up for additional details.)
With the network architecture in place, I ran through four different scenarios, or four different combinations of input features, while keeping the network architecture constant. I’ll outline the results first, followed by a brief discussion.
Scenario #1: Plate Discipline Only
With what probability could we predict whether someone’s wOBA is over .320 using only plate discipline statistics, while knowing nothing at all about what happens when bat meets ball? This was my first scenario. In particular, the input features used in the training set were – all normalized – zone contact rate, zone swing rate, zone swing and miss rate, outside zone contact rate, outside zone swing rate, and outside zone swing and miss rate.

I had 80% of my overall dataset in the training set, and 20% in the test set. The network is trained on the training set, and the test set is used to gauge the accuracy of the network on data it hasn’t seen before. This resulted in 791 items in the training set, and 198 items in the test set. Here are the results after the network has learned its parameters following 15 passes through the training set:

Test set performance for scenario #1:

That’s about a 67% prediction accuracy on the training set, and about 69% on the test set. In other words, the probability that the network will be able to correctly predict whether a hitter’s wOBA will be above .320, using nothing more than their plate discipline statistics, is about 0.7. The fact that the training and test set accuracies are reasonably close – the test set accuracy actually being a bit higher – means that the network is not overfitting the training set either.
Scenario #2: Plate Discipline + Exit Velocity
While 70% is not a bad starting point, how much more accurate could the predictions of the network get if I added a feature with some actual batted ball information? For the second scenario, I added a seventh feature – the average normalized exit velocity. Here is the performance on the training set.
(As a side note, the training and test set splits were fixed for all the different scenarios. What this means is that the same 791 player-seasons were used in the training set every time.)

Test set performance for scenario #2:

The accuracy increased on both the training set and the test set; we’re now in the ballpark of 0.7 – 0.75 probability of the network making the correct prediction as to whether someone’s wOBA will be above .320 or not. Intuitively this makes sense: wOBA is calculated based on batted ball outcomes (and walks), and so adding a relevant batted ball parameter as a feature – such as exit velocity – should increase the accuracy of any wOBA prediction.
Scenario #3: Plate Discipline + Barrel Rate
Would using a barrel rate instead of the exit velocity lead to more accurate predictions? After all, the barrel rate combines two batted ball features – exit velocity and launch angle. Maybe the addition of the launch angle component would help improve accuracy. For scenario #3, I used seven features in the input layer again: the six plate discipline statistics, and the average normalized barrel rate. Here is the performance on the training set:
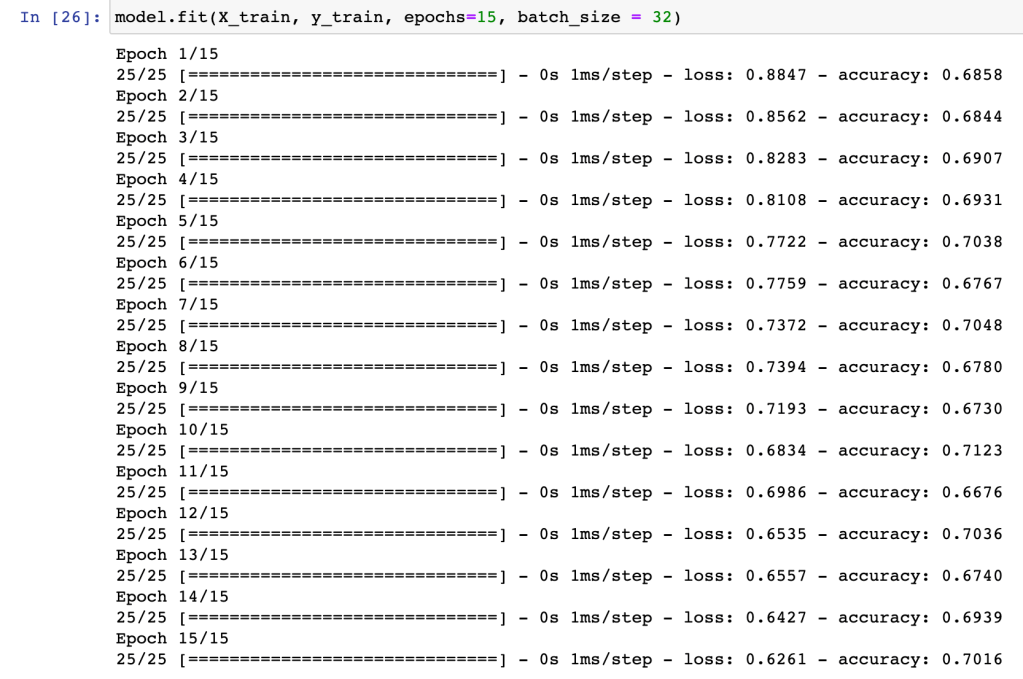
Test set performance for scenario #3:

The predictions of the network using the barrel rate as the seventh feature increased the accuracy of predictions compared to just using the plate discipline statistics alone, but they were less accurate than the predictions generated using the average exit velocity as the seventh feature. As to why average exit velocity led to better predictions than barrel rate – I’m guessing it’s because it is a more granular feature.
Let’s say Batter A hits three balls – a “barrel” at 97mph, and two “non-barrels” at 92mph. And let’s say Batter B hits three balls – a “barrel” at 97mph, and two “non-barrels” at 82mph. Their barrel rate will be the same, yet the average exit velocity will be different. Either way, the exit velocity provided the network with “more useful” information than the barrel rate did.
Scenario #4: Plate Discipline + Exit Velocity + Barrel Rate
For the final scenario, I used eight input features: the six plate discipline measures, the average normalized exit velocity, and the normalized barrel rate. Theoretically, this should lead to the most accurate prediction, as we’re adding the most detailed batted ball information to the plate discipline measures. This is the performance of the network on the training set:
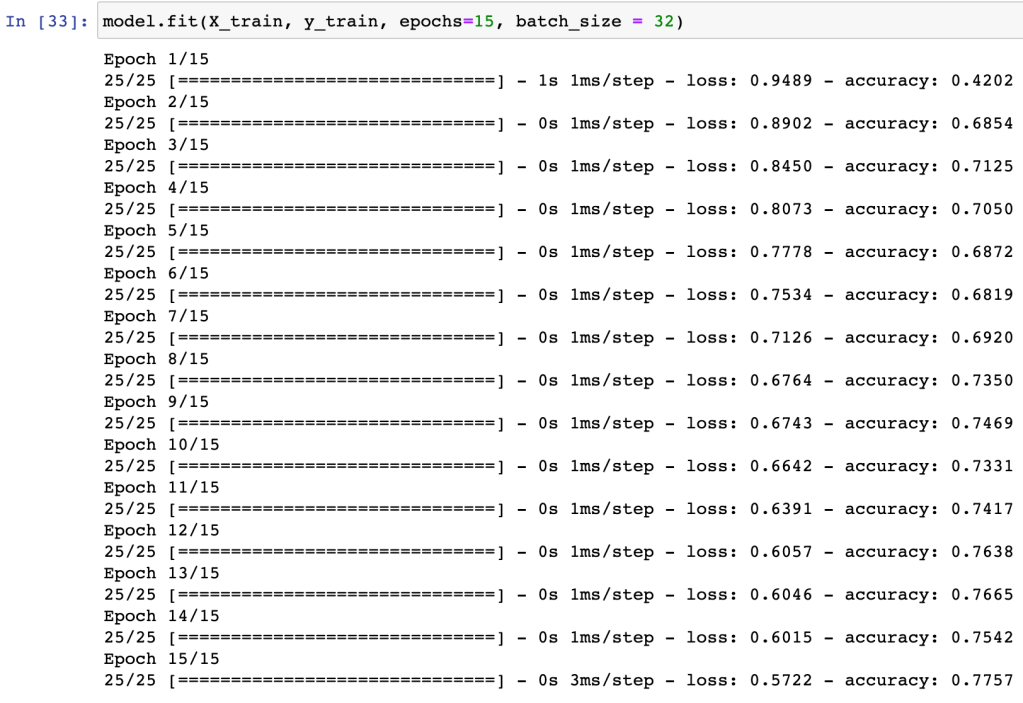
Test set performance for scenario #4:

Utilizing all eight of the available features puts us in the ballpark of 80% accuracy of predictions. The fact that adding the barrel rate increased the accuracy as compared to the exit velocity alone, passes the smell test: while barrel rate contains some of the exit velocity information in it, it is sufficiently distinct from exit velocity so that it proved useful having it as a separate feature.
Summary & Discussion
| Scenario | Training Set Accuracy | Test Set Accuracy |
| Plate Discipline | 66.92% | 69.19% |
| Plate Discipline + EV | 73.52% | 75.25% |
| Plate Discipline + Barrel | 70.16% | 71.72% |
| Plate Discipline + EV + Barrel | 77.57% | 81.31% |
As it turns one can get about 80% of the way towards predicting whether someone will be an above average offensive contributor using their plate discipline statistics, their average exit velocity, and their barrel rate in this particular setup. One of the advantages of using a neural network is that the network is able to learn the various non-linear interplays between the input features. For example: let’s say a player has a relatively high out-of-zone chase rate. How high of an outside-of-zone contact rate would he need to have, keeping everything else constant, to get his wOBA over .320? Is it realistic? Or let’s say a player is currently sitting at a wOBA of .310. If we keep his plate discipline statistics constant, how much harder would he have to hit the ball to get his wOBA over .320? There are usually multiple avenues to improve a batter’s performance. Once the network is trained, its predictions can serve as a starting point in evaluating which of the avenues to explore, and which would require an improvement that might be beyond the batter’s reach.
To further improve the performance of the network past the 80% accuracy, there are two ways that one could take. Either change the network architecture, such as the number of hidden layers, the number of units in a layer, the activation functions etc. Or, use additional features that the network could find useful. For example, one could incorporate the percentage breakdown of pull-straight-opposite field hits for a batter. A batted ball with a certain exit velocity and launch angle hit directly over second base could be a single, while a batted ball with the same characteristics hit down the line could go for extra bases. Furthermore, since the test set accuracy actually exceeds the training set accuracy in all four scenarios, simply obtaining additional data is not likely to improve the network’s performance.
Finally, I’m sure that this is a baby version of what major league teams use. If the network’s output and the actual wOBA of a player disagree, the player could be candidate for regression, warrant a deeper dive into their data, or an additional look by the scouts. It would also be interesting to see, how effective minor league plate discipline and exit velocity data would be in predicting major league wOBA using a setup similar to this one.
For those interested, code for the neural network here.
